This article is the third part of our “How IoT Works” series, in which we’ll cover the key elements of IoT in a simple, understandable way.
Internet of Things (IoT) solutions typically consist of four fundamental elements:
- Sensors
- Connectivity
- Data Processing
- User Interface
In the previous articles covering sensors and connectivity, we learned how IoT sensors collect data and how the data is sent to a cloud service by using a network solution. The next step is to make the data useful.
In this article, we’ll concentrate on the third element on the list: data processing.
What Is Data Processing?
The volume and pace at which data is produced nowadays is unbelievable. According to McKinsey, 90% of all data in the world today has been produced just in the past two years.
In order to make sense of the massive amount of data our IoT sensors collect, we need to process it. Wikipedia explains data processing as “the collection and manipulation of items of data to produce meaningful information.” In other words, the purpose of data processing is to convert raw data to something useful. Something the end user can react to.
We should also take notice of the difference between data and information. Data refers to raw, unorganized facts, and it usually is fairly useless until it is processed. Once the data is processed, it is called information.
Data is the input, or raw material, of data processing. The output of data processing is information. The output can be presented in different forms, such as plain text files, charts, spreadsheets, or images.
Data Processing Cycle
So how does data processing work? The process usually follows a cycle which consists of three basic stages: input, processing, and output.
To keep this article simple, we are not going to dive deep into the technical details of the stages of data processing. Instead, we’ll provide you with a very general and simple explanation of each stage.
Input
Input is the first stage of the data processing cycle. It is a stage in which the collected data is converted into a machine-readable form so that a computer can process it. This is a very important stage since the data processing output is completely dependent on the input data (“garbage in – garbage out”).
Processing
In the processing stage, a computer transforms the raw data into information. The transformation is carried out by using different data manipulation techniques, such as:
- Classification: Data is classified into different groups.
- Sorting: Data is arranged in some kind of an order (e.g. alphabetical).
- Calculation: Arithmetic and logical operations are performed on numeric data.
Output
In the last stage, output is received. This is the stage where the processed data is converted into human-readable form and presented to the end user as useful information. Also, the output of data processing can be stored for future use.
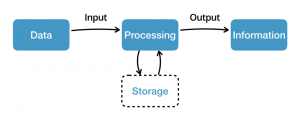
For example, the stored information might be used as input for further processing. It can also be utilized for building historical references that will allow detecting trends in the future.
Considerations for Data Processing in IoT
Now that we know how data processing works in general, we can introduce some considerations when it comes to data processing in IoT.
Desired Output
Even though the data processing cycle starts with the input stage, we should first think about the desired output. In other words, what are the questions that should be answered with the help of IoT? What kind of information are we interested in?
One example use case is to receive an alert whenever a manufacturing machine’s temperature exceeds a threshold limit.
Storing of Data
Once we are clear on what the desired output is, we have to find a way to obtain it. The data collected by the sensor devices has to be stored in a proper form so that it can be transformed into the information we are looking for.
As an example, we could receive data periodically (e.g. every 10 minutes) when a machine is running. We might want to use that data to calculate how many hours the machine has been running since the last maintenance. We could also detect trends among that data, and create estimations about when a specific amount of hours will be reached if the usage will continue on the same level.
Due to the potentially massive amount of data our sensors collect, we should invest in a scalable cloud service to be able to store the data. That said, we should also develop a data retention policy and accept that it is not rational to keep all the IoT data forever. The more we have data and the longer we keep it, the more it costs to store it. On the other hand, less data means less insights and historical references. Thus, we have to prioritize and balance between costs and the amount of data we want to store.
Frequency of Updates
Before implementing data processing it is important to decide what is a good balance between the frequency of updates and the consumption of resources (e.g. calculation capacity, power). The “good balance” depends entirely on the IoT use case.
In some use cases it is essential to know right away how the collected data affects the output. This however requires real-time data processing which can be very resource-consuming. In some other use cases it is enough to process the collected data, for example, once a day.
Data Processing Tools
Lastly, there are multiple data processing tools to choose from. For example, there are many software solutions available for different IoT use cases. One example is Trackinno cloud service, which is designed for asset and maintenance management purposes. These softwares are able to process data and present the information to the end user in an easily understandable form.
Alternatively, we could use an IoT platform to build our own data storage. The data storage can then be used to create customized reports. We could also hire an analyst, who would create the reports for us.
A Note about Data Processing
Previously, we have explained that the data collected by sensor devices is sent to a cloud service for data processing. However, that is not always the case. There are also different approaches to where (or when) the data is processed.
For example, the data can be processed before sending it to the cloud, which is enabled by edge computing. Edge computing allows the data to be processed near to its origin (the sensor devices). The data is transferred from sensor devices to a local edge computing system, which processes and stores the data, and only then sends it to the cloud. Also, the system could compile the processed data and send it to the cloud e.g. once a day.
The good thing about edge computing is that only the important information is sent over the network. This requires less bandwidth from the network and also saves the sensor devices’ batteries. Also, the data can be processed faster when it is done near the sensor device.
What’s Next in the IoT Workflow?
So far we have collected the data by sensor devices, used a network solution to send the data to a cloud service, and transformed the data into useful information. Next, it is time to present the results for the end user. Stay tuned for our next article “How IoT Works – Part 4: User Interface”!
